網路爬蟲
貼近生活的上網自動化
- 前言
- 什麼是網路爬蟲
- 網路爬蟲種類
目錄
- requests介紹
- requests.GET
- API
- requests.POST
- httpbin.org
- robots.txt協議
requests
selenium

林承諺
- 成電38社長兼公關
- 看小說
- 變魔術
- 2009.07.08
- ig: wallacelin8
- YT香菇時刻
前言
我從小就有一個夢想 : 開遊戲外掛

我摸索了好幾年,沒想過是要用到【網路爬蟲】這個領域

或許這聽起來很陌生 很困難

但這讓我實現了一個從小的夢想

也是他,開啟了我對程式的興趣

班級自主學習發表 - 票選第一

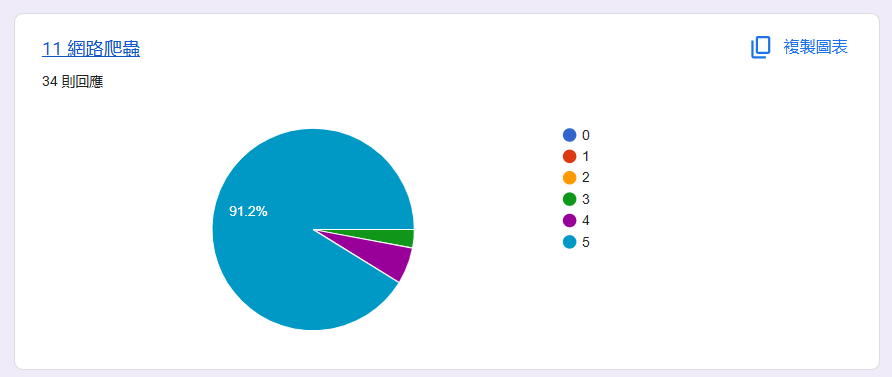
好評率百分百
2025 高一下全校自主學習發表

2025 高一下全校自主學習發表
發表內容

這堂課能帶給你甚麼


拿到天氣資料
遊戲外掛
搶票系統
Slido 課堂中及時發問
QR CODE
什麼是網路爬蟲




每天都重複?
好無聊 !

AUTO
讓電腦自動完成日常瑣事
定義
用程式模擬人類在網路上的行為
是怎麼做的?
抓取資料 (GET)
傳送資料 (POST)
常用的有3種模式
自動點擊
就像你上網找歌單
網路爬蟲
你啟動它
輸出
進入kkbox
找到資料
記下來
進入kkbox
找到資料
記下來
抓取資料GET範例
想找歌單? 按一下就好


進入kkbox
找到資料
記下來
而且程式不會分心滑到其他地方
傳送資料POST範例
就像你填春遊報名表
進入表單
填寫資料
送出
網路爬蟲
你啟動它
輸出ok
進入表單
準備資料
送到伺服器
想去春遊? 按一下就好
而且程式可以一秒送出很多表單
進入表單
準備資料
送到伺服器

用途:
- 機器學習、監控資料、數據分析
- 從網路上擷取資料
- 向伺服器發送指令
看得到的網頁,理論上都可以「爬」
網路爬蟲種類
網路爬蟲可以用那些語言?
| 語法 | 優點 | 套件 |
|---|---|---|
| Python | 易學,初學者首選 | requests BeautifulSoup Selenium |
| JavaScript | 模擬網頁行為,能抓取動態資料 | axios, cheerio |
| Java | 穩定,適合大量處理 | Jsoup, Selenium |
| C# | 整合Windows系統 | HtmlAgilityPack |
Python ✅
入門最快
只要語言能發 request、能處理 HTML,就能寫爬蟲
但
網路爬蟲三大套件



網路爬蟲三件套
直接發送請求
requests
整理接收結果
Beautifulsoup
模擬真實使用者
Selenium
爬蟲類型比較
| 類型 | 用途 | 特色 |
|---|---|---|
| requests + BeautifulSoup | 靜態網頁 | 直接抓下整個網頁的原始碼 |
| Selenium | 動態網頁 | 模擬人類操作,可取得動態數值 |
| API爬蟲 | 伺服器端口 | 官方資料接口、回傳指定資料 |
在後面都會教到
requests初探
pip install requests
# PRESENTING CODE
requests安裝
- Python外部函式庫
在終端機輸入 :
# PRESENTING CODE
requests第一步
引入函式庫:
import requests# PRESENTING CODE
requests怎麼寫
發出第一個指令:基本語法
url = "https://ckcsc.net/"
data = {"key": "example"}
response = requests.get(url)
response = requests.post(url, json=data)有兩種?
GET? POST?
# PRESENTING CODE
requests
| 屬性 | 用途 | 範例 |
|---|---|---|
| requests.get | 向伺服器【請求】資料 | 瀏覽網頁 |
| request.post | 向伺服器【發送】資料 | 提交表單 |
requests.GET



透過瀏覽器互動
平時上網

取得網頁的原始碼
發送取得網頁的請求
回復請求資料
網路爬蟲
requests.GET
# PRESENTING CODE
import requests
a = requests.get("https://ckcsc.net")
print(a)賦值
使用模組
使用GET
要取得的網址
執行看看?
requests.GET
# PRESENTING CODE
import requests
a = requests.get("https://ckcsc.net")
print(a)輸出的是200,怎麼不是整個網站?
<Response [200]>直接print,預設會顯示 HTTP 回應
【狀態碼】
常見狀態碼
| 數字 | 英文顯示 | 中文意義 |
|---|---|---|
| 200 | OK | 請求成功 |
| 404 | Not Found | 請求的資源不存在 |
| 500 | Internal Server Error | 伺服器內部發生錯誤 |
快速得知請求的成功與否
requests.GET
# PRESENTING CODE
import requests
a = requests.get("https://ckcsc.net")
print(a.text)讓它輸出網站的整個內容
輸出【文字屬性】
輸出結果
看的出來成電社網大部分都是JavaScript動態生成
反反爬蟲
# PRESENTING CODE
import requests
a = requests.get("https://tw.yahoo.com/")
print(a.text)換成爬取雅虎奇摩的首頁試試看
輸出結果
Edge: Too Many Requests<Response [429]>.text
Why?
沒有出現網站而是出現錯誤?
網站的反爬蟲
- 網站為了保護自身資料和伺服器資源,不讓爬蟲取得資訊
常見的手段:
- 檢查 User-Agent
- 限制請求頻率
- 驗證碼...
解決辦法
✔️偽裝成正常的瀏覽器
✔️不要告訴他你是Python
❗新增 User-Agent
什麼是User-Agent
常見的請求 Header,用於識別發送請求的應用程式
不告訴你
我是Python,請求網頁
就像是你的電腦的身分證,伺服器會接收到
給你html
我是Mozilla/5.0 (Windows NT 10.0; Win64; x64),請求網頁
尋找你的User-Agent
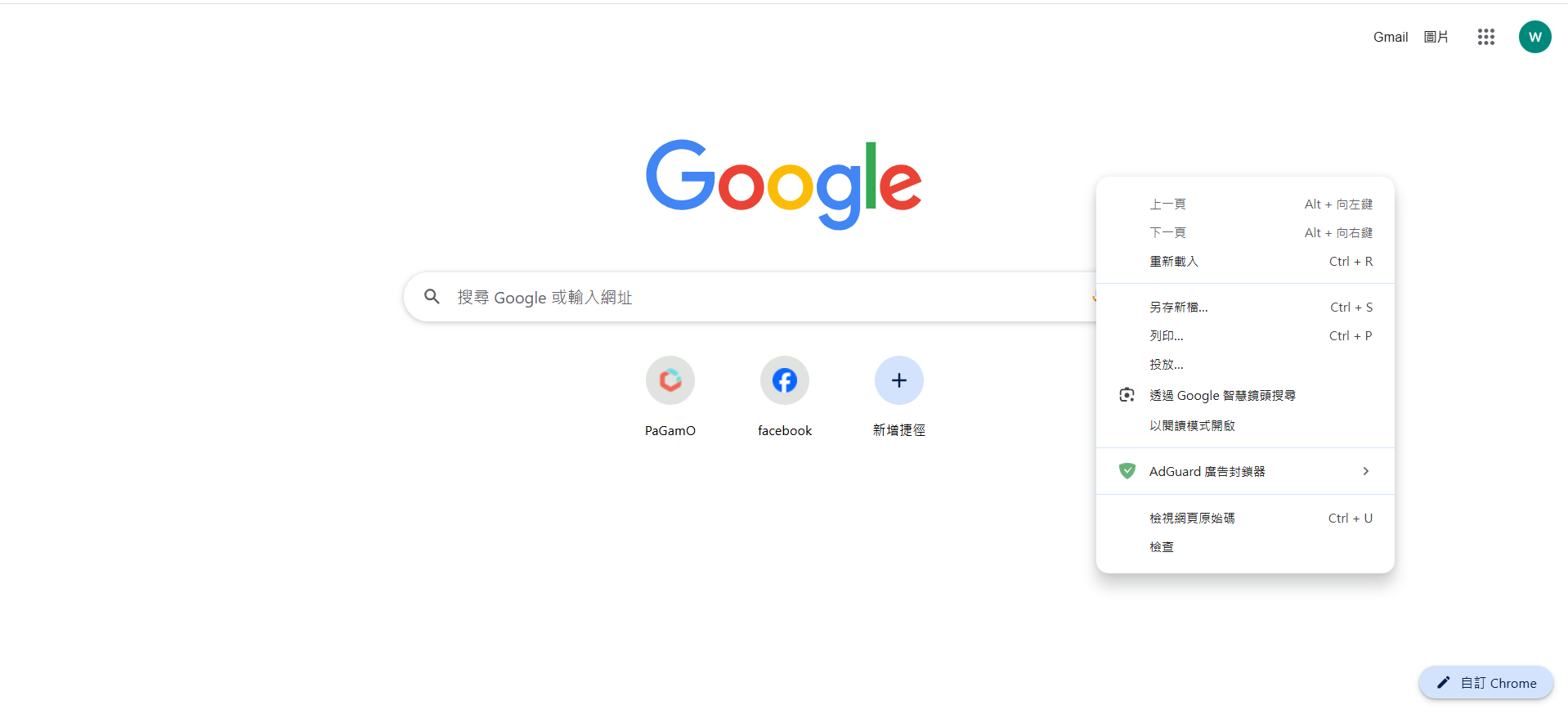
1.
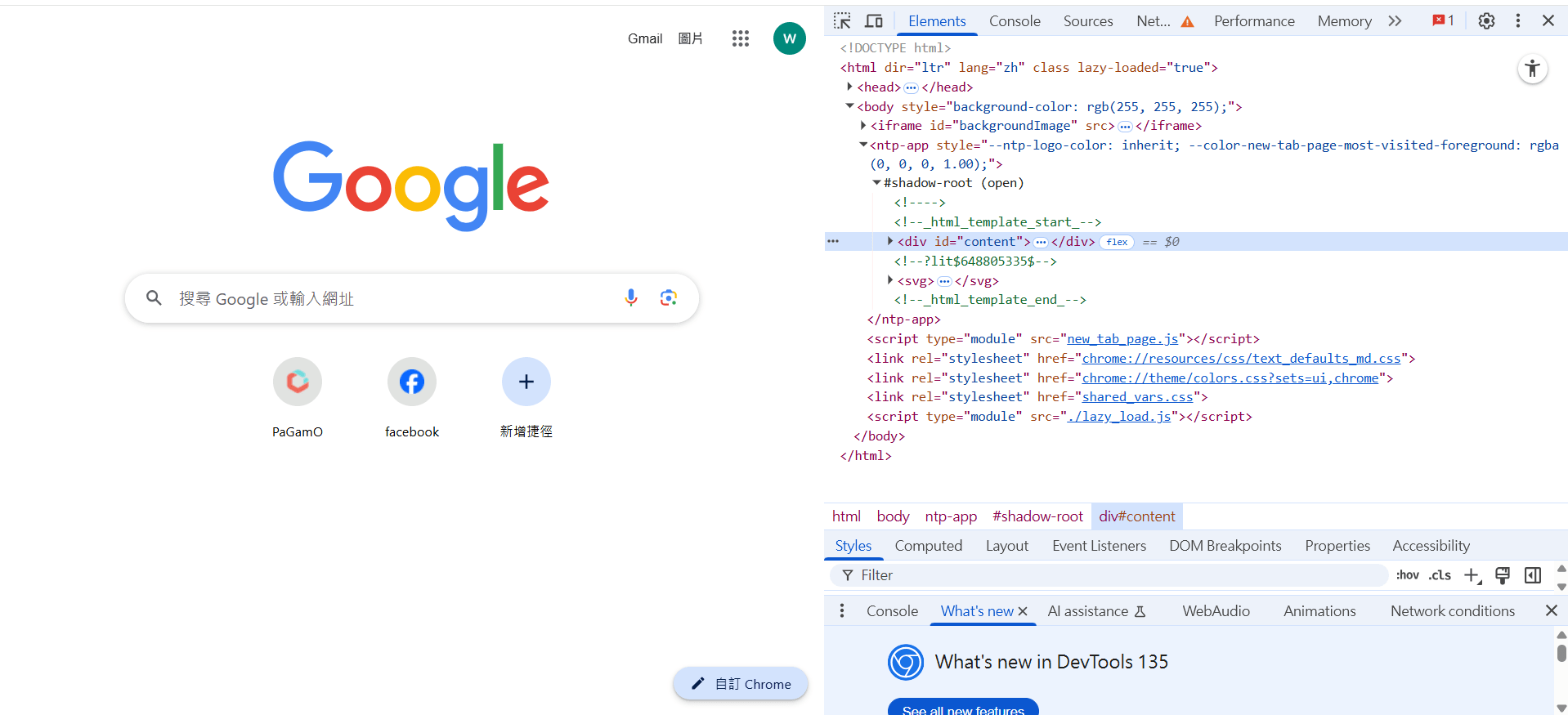
2.
檢查
network
尋找你的User-Agent
3.
4.

重新整理
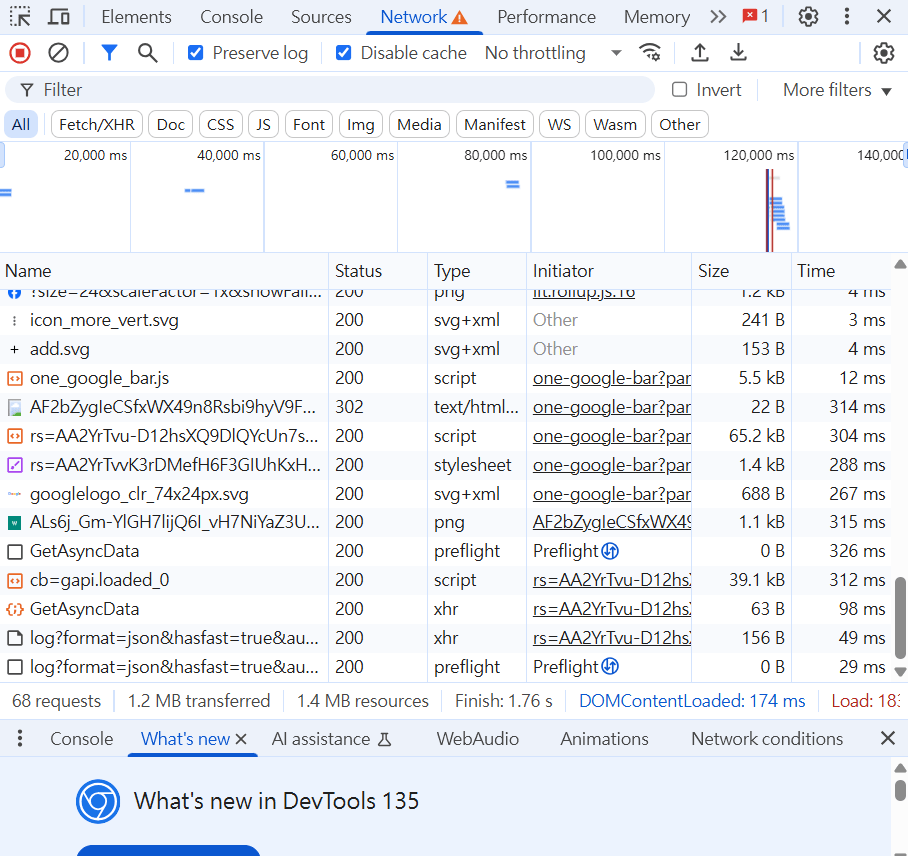
隨便點一樣請求
5.
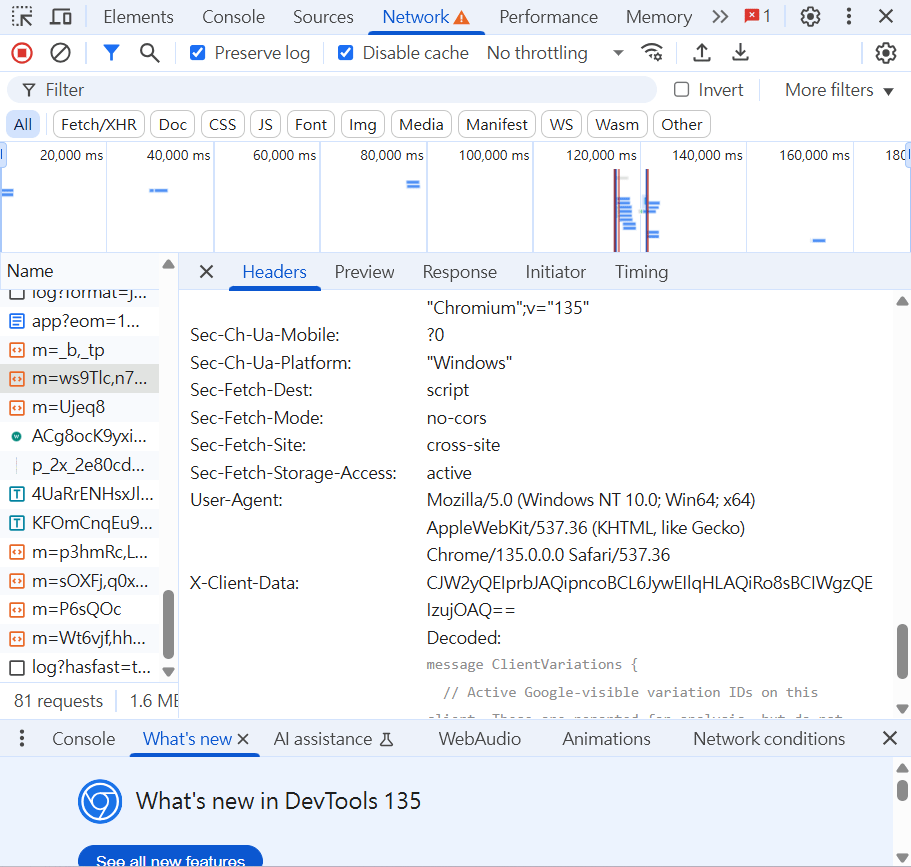
往下滑,會找到User-Agent
requests.GET
# PRESENTING CODE
import requests
Useragent = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
a = requests.get("https://tw.yahoo.com/", headers=Useragent)
print(a.text)實作User-Agent
將User-Agent以字典形式儲存並附在括號中,參數名稱header後面
把電腦的身分證附在請求裡面
requests.GET比較
# PRESENTING CODE
import requests
Useragent = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
a = requests.get("https://tw.yahoo.com/", headers=Useragent)
print(a.text)import requests
a = requests.get("https://tw.yahoo.com/")
print(a.text)原本的
requests.GET
# PRESENTING CODE
輸出結果
成功回傳整個網頁

看到新聞 :
requests.timeout
# PRESENTING CODE
import requests
url = "https://httpbin.org/delay/5"
Useragent = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=Useragent)
print(response.text)實測看看這個網站
拖了好久才輸出
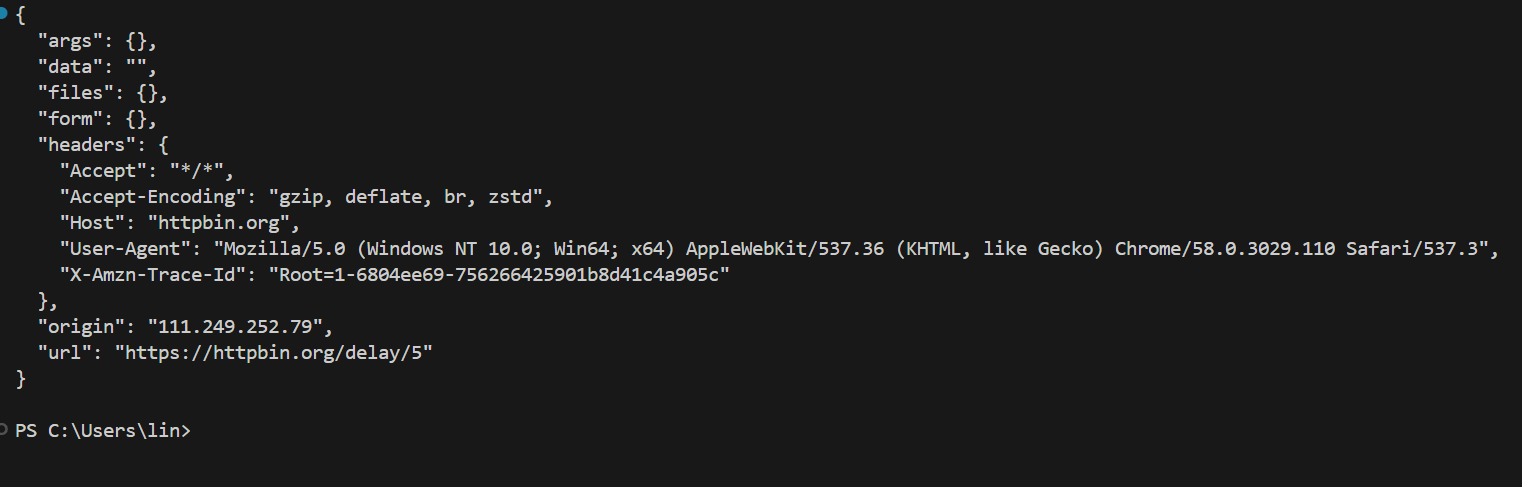
實測 !
requests.timeout
# PRESENTING CODE
import requests
url = "https://httpbin.org/delay/5"
Useragent = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=Useragent)
print(response.text)設定延遲5秒才輸出
生活應用? 常常發生?
requests.timeout
- requests會等待伺服器回應,才進行下一步
- 伺服器可能因負載過高、網路問題、防火牆阻擋等而不回應
- 程式會一直等待回應,無限輪迴,導致卡住會閃退
✔️讓程式適可而止,適時放棄
❗新增 timeout
✔️像是抓取跑很慢的網站
requests.timeout
# PRESENTING CODE
response = requests.get(url, timeout=5)基本語法:
設定等待不超過5秒
requests.timeout
# PRESENTING CODE
import requests
url = "https://httpbin.org/delay/5"
try:
response = requests.get(url, timeout=3)
print(f"發送成功")
print(response.text)
except: #如果沒成功執行則報錯
print("伺服器在3秒內沒有回應")實際演練:
伺服器在3秒內沒有回應在嘗試3秒後就會放棄
只能在指定秒數內執行完成,否則就會報錯
練習題:
抓取台北市政府官網,要使用User-Agent並在嘗試最多3秒後放棄
# PRESENTING CODE
答案:
import requests
Useragent = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
try:
a = requests.get("https://www.gov.taipei/", headers=Useragent,timeout=3)
print(a.text)
except:
print("伺服器在3秒內沒有回應")# PRESENTING CODE
答案:
可以看到蔣萬安最近做了甚麼
更多值得學習
cookies
- 如何使用發送帶有Cookie的請求及獲取伺服器Cookie
proxiex
- 如何使用代理伺服器隱藏自己ip位置
API
- 允許不同軟體之間互相溝通和交換資料
- 讓你不需要知道內部實際結構,即可獲取資料
- 爬蟲可以透過 API 來獲取結構化資料,不用直接解析 HTML
定義
郵差
( API )
寄信者
( 使用者 )
面試官
( 伺服器 )
寄信
傳送
傳送
送回



✅填地址和郵遞區號
✅填面試官要的個資
❌知道怎麼送信
❌知道面試官怎麼審核
投面試履歷
乖乖在家就會送回來 不用懂
你只需要知道✅
- 可用的功能或服務: 另一個軟體可以請求或使用的特定操作
- 發出請求: 請求的格式、需要的資料和參數
- 接收回應: 回應的格式和包含的資料
特點
你不需要知❌
-
底層系統細節: 哪種程式語言、資料庫結構、演算法等。
-
系統基礎架構: 部署在哪裡、使用了哪些伺服器、網路拓撲結構等
-
版本細節:只要 API 的介面保持向後兼容,我們通常不需要深入了解目標系統的具體版本號和內部更新細節。
輕鬆易懂
範例
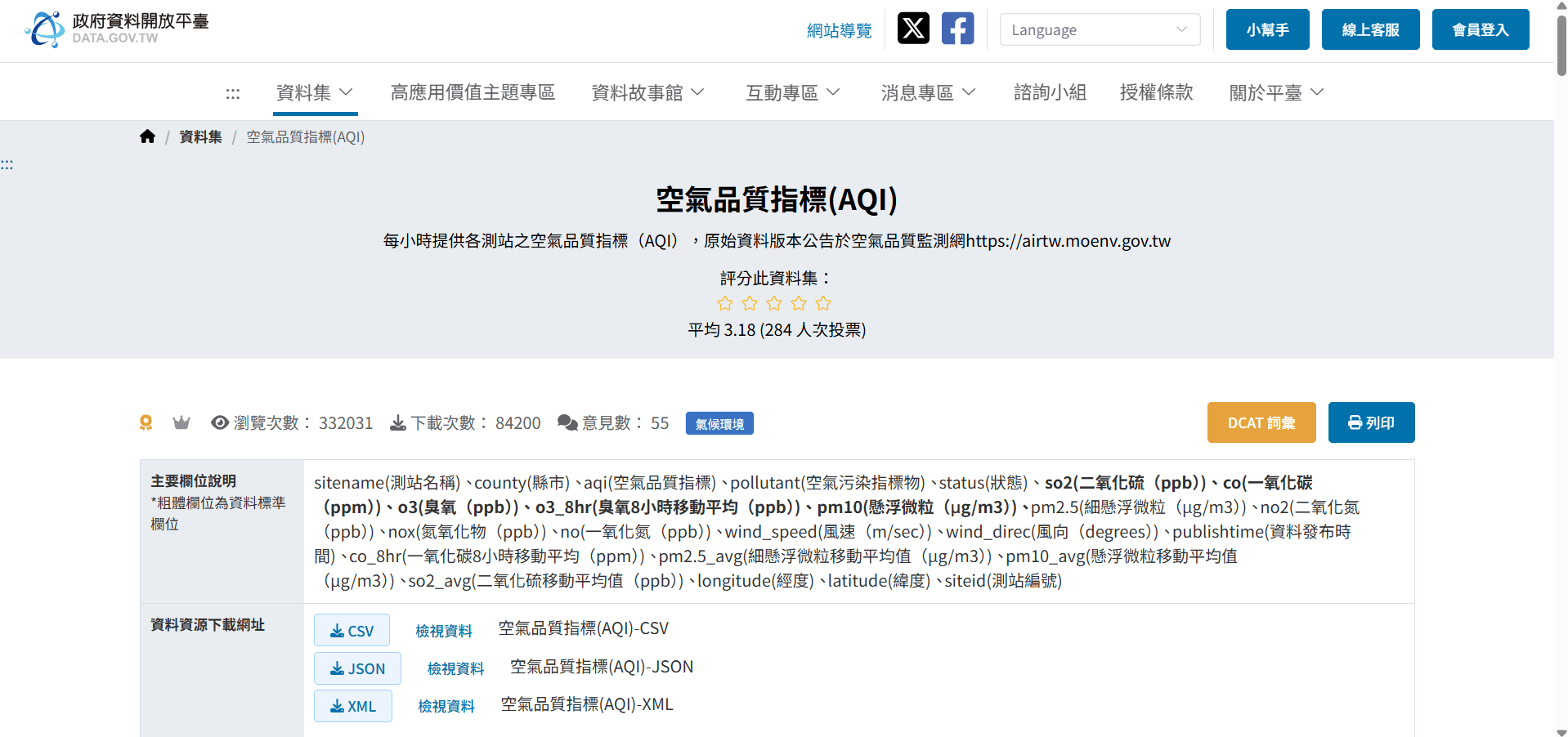
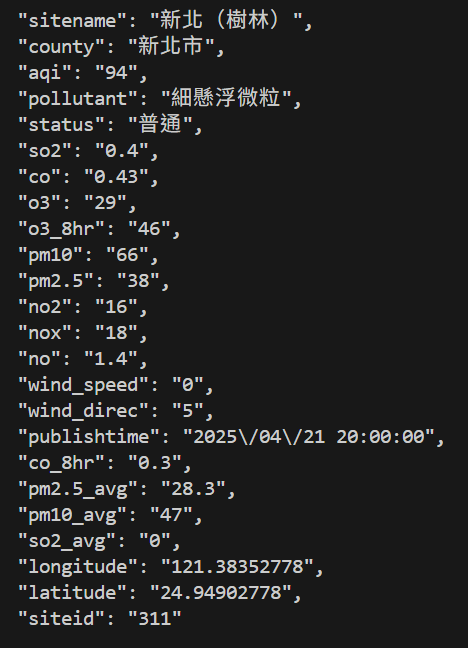
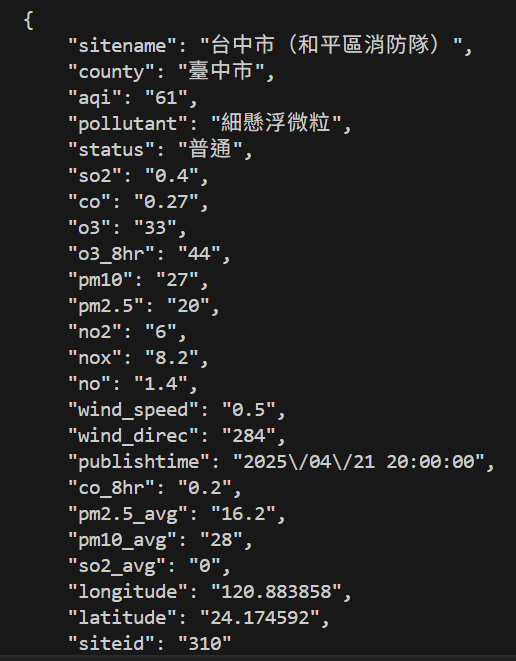
抓取空氣品質指標
有無API差異
不使用API
使用API
使用他「專門提供做這件事的連結」 ,取得整理好的資料

https://data.moenv.gov.tw/api/v2/aqx_p_432?api_key=9b651a1b-0732-418e-b4e9-e784417cadef&limit=1000&sort=ImportDate%20desc&format=JSON"
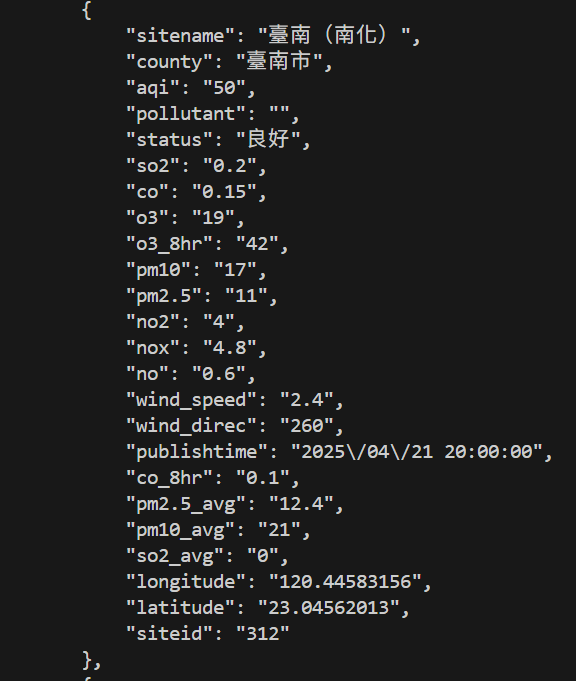
範例
# PRESENTING CODE
import requests
url = "https://data.moenv.gov.tw/api/v2/aqx_p_432?api_key=9b651a1b-0732-418e-b4e9-e784417cadef&limit=1000&sort=ImportDate%20desc&format=JSON"
Useragent = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=Useragent)
print(response.text)輸出:
# PRESENTING CODE
如何解析?
我是樹林人
.json
- API回傳的通常是JSON格式
- 是種常見的輕量級資料交換格式
❓Python看不懂
✔️轉換成Python字典格式
❗使用.JSON解碼
.json
- JSON {物件} 會被轉換成 Python 字典 (dictionary)。
- JSON [陣列] 會被轉換成 Python 列表 (list)。
語法:
response = (requests.get(url, headers=Useragent)).json()在回傳後的資料加上.json()
注意事項:只有格式為json時才會運作,否則會報錯
# PRESENTING CODE
.JSON範例
import requests
url = "https://data.moenv.gov.tw/api/v2/aqx_p_432?api_key=9b651a1b-0732-418e-b4e9-e784417cadef&limit=1000&sort=ImportDate%20desc&format=JSON"
Useragent = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = (requests.get(url, headers=Useragent)).json()
print(response)輸出:

✅輸出Python字典格式
.JSON後取得數值
❓轉換成字典之後,如何取得其中的數值?
✔️直接取得字典內的數值
❗使用KEY處理巢狀結構
ex.取得pm10=多少?
# PRESENTING CODE
獲取KEY
data = {
'status': 'success',
'result': {
'user': {
'id': 123,
'profile': {
'name': 'Alice',
'age': 30,
'address': {
'city': 'Taipei',
'zipcode': '100'
}
},
'hobbies': ['reading', 'coding']
}
}
}
user_id = data['result']['user']['id']
print(user_id)基本語法
依序取得鍵中的鑑中的值
data['result'] -> {'user': ...}
data['result']['user'] -> {'id': 123, 'profile': ...}
data['result']['user']['id'] -> 123# PRESENTING CODE
獲取pm10作法詳解
import requests
import json
url = "https://data.moenv.gov.tw/api/v2/aqx_p_432?api_key=9b651a1b-0732-418e-b4e9-e784417cadef&limit=1000&sort=ImportDate%20desc&format=JSON"
Useragent = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=Useragent)
data = response.json()
for record in data['records']:
if record['sitename'] == '屏東':
print(record['pm10'])- 資料最外面是列表[],中間是字典{}
- 遍歷所有record
- 找到【屏東】就停下
- 尋找屏東的pm10
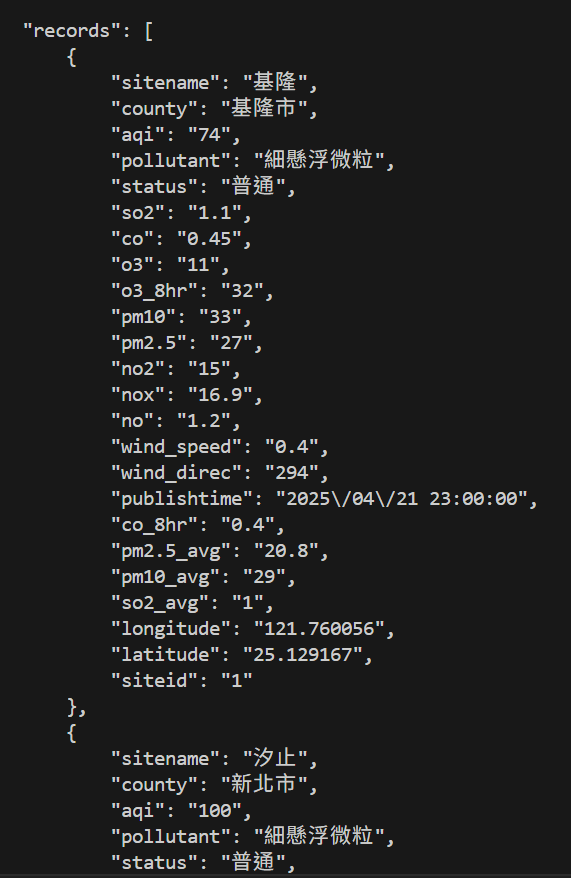
30自己尋找API
- 不是所有東西都有提供公開的API
❓想取得那種資料怎麼辦
✔️自己找&直接get讓他回傳
ex.網頁遊戲的個人資料頁面
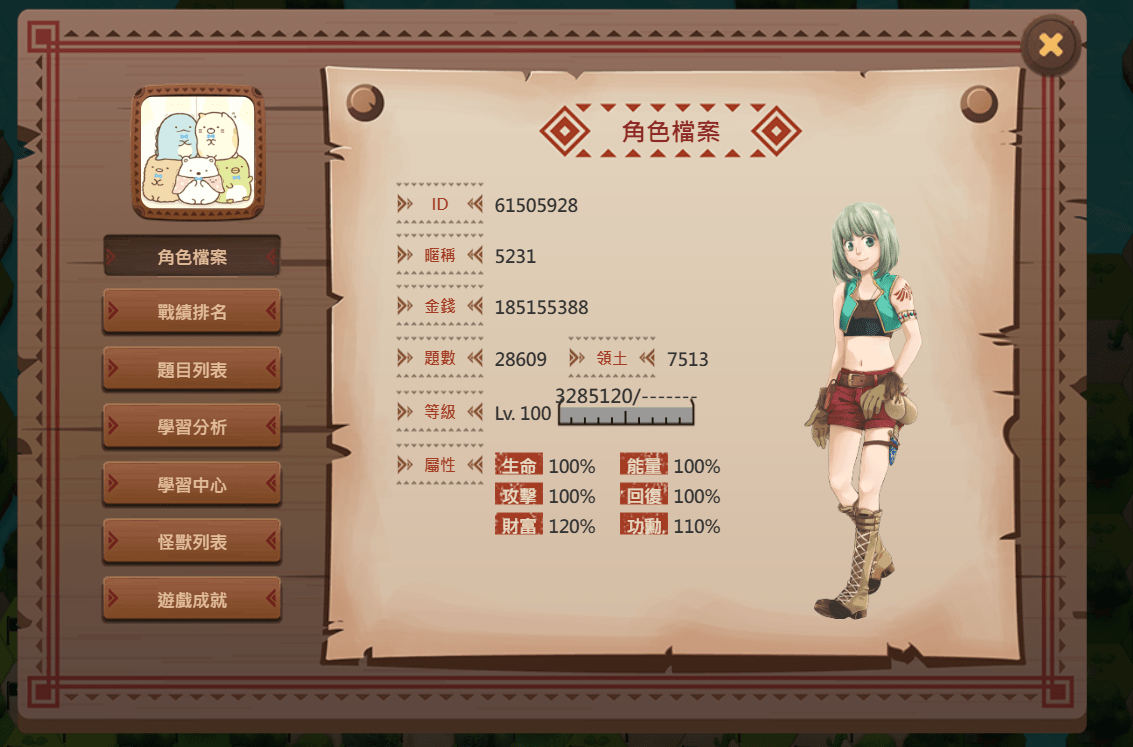
- 他不可能給你API讓你抓取別人個資
- 但你可以自己找API取得這些數值
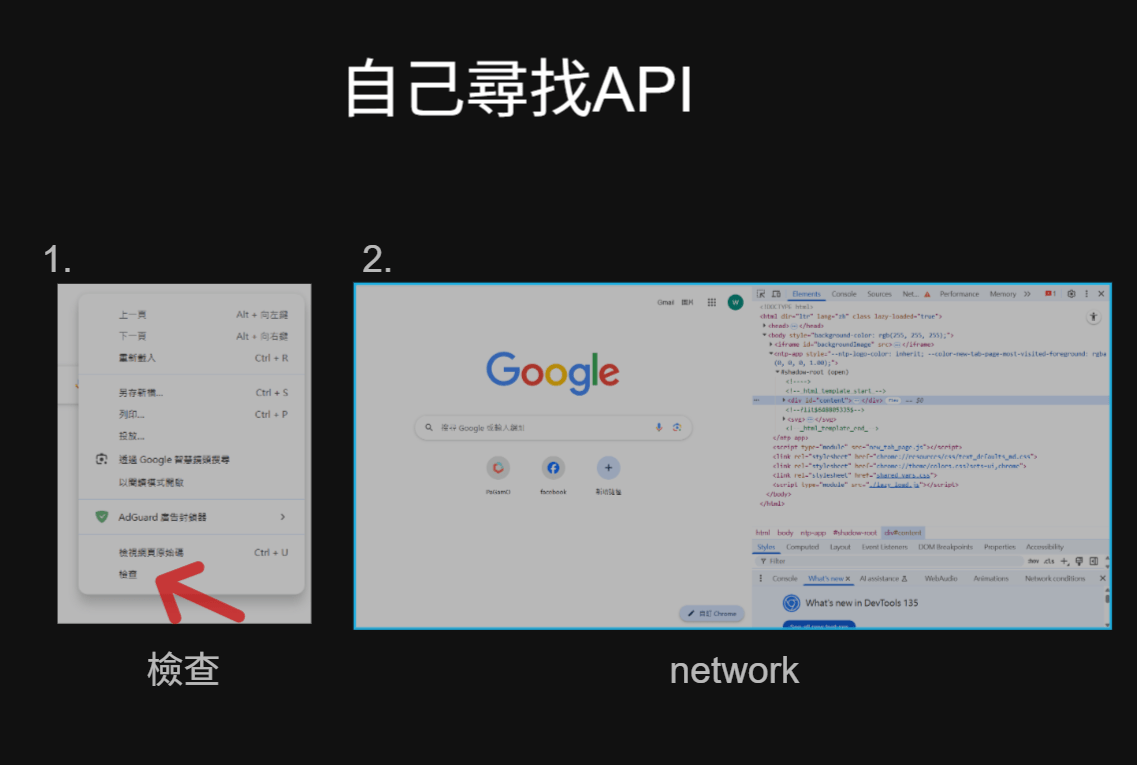
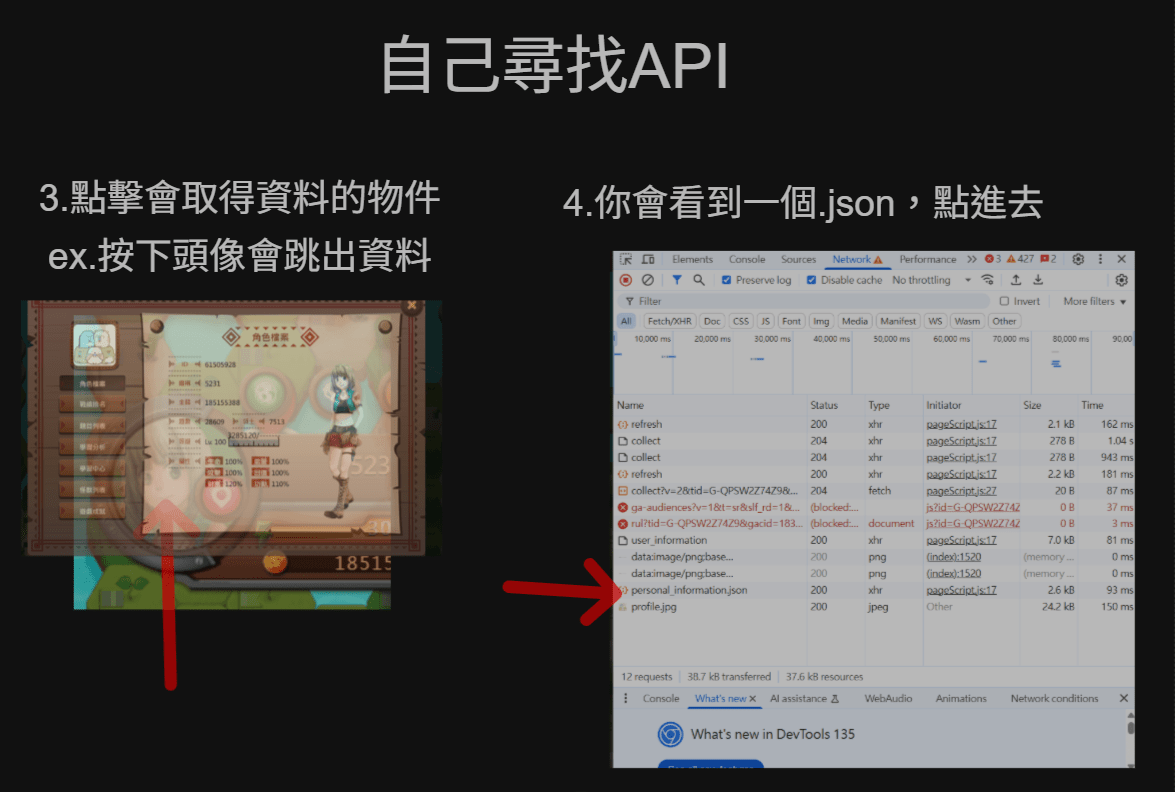
自己尋找API
1.
2.
檢查
network
自己尋找API
3.點擊會取得資料的物件
ex.按下頭像會跳出資料
4.你會看到一個.json,點進去
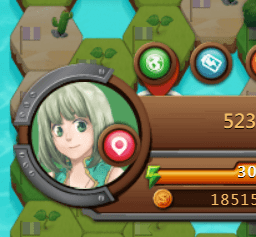
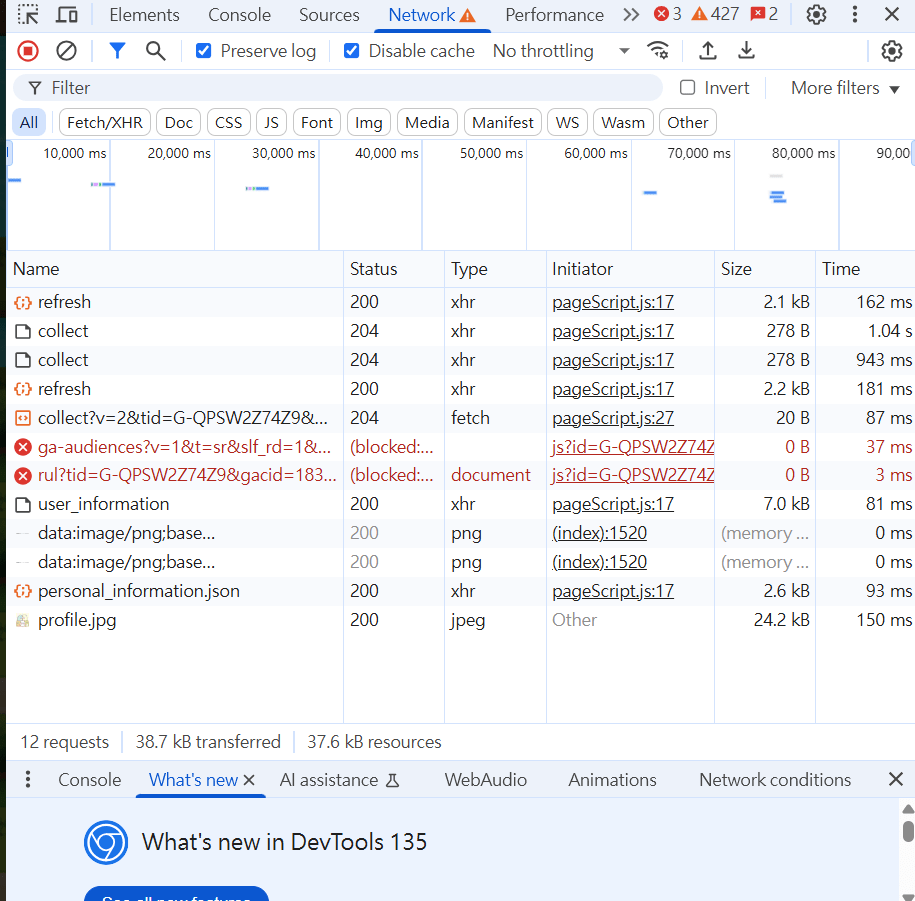
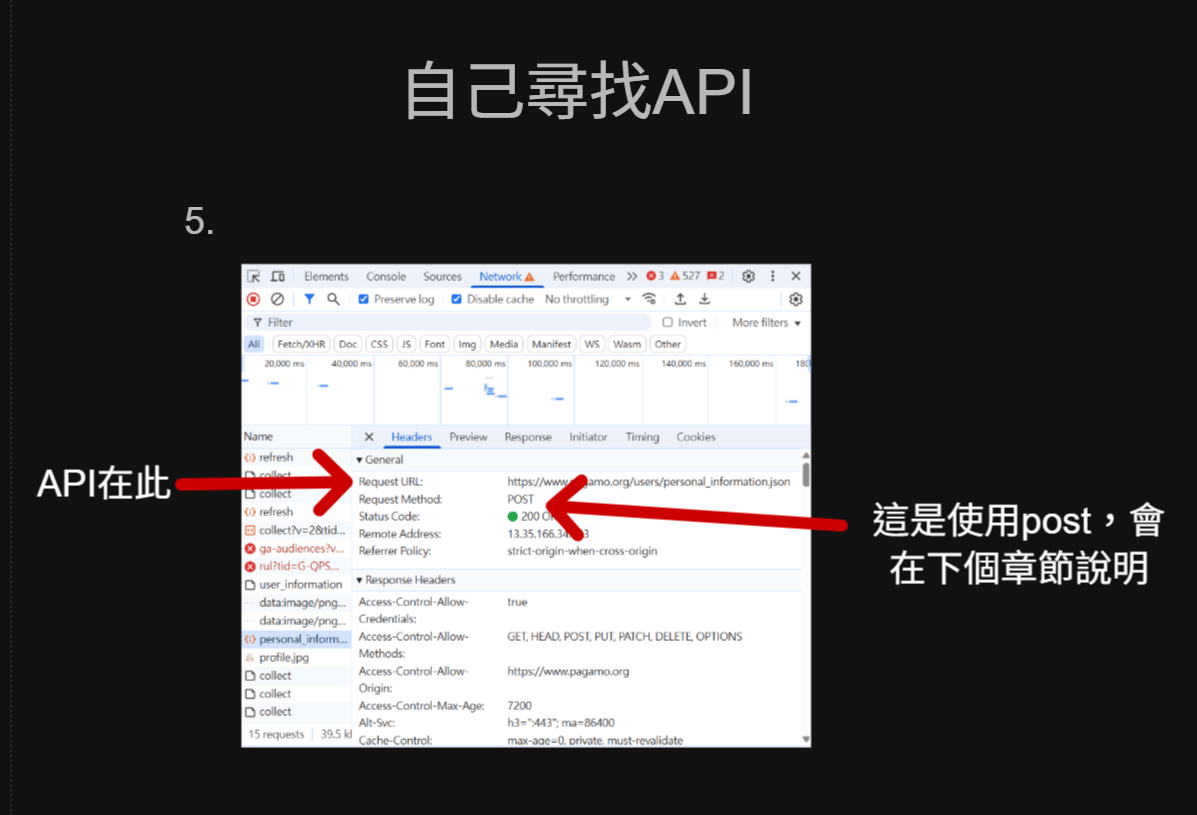
自己尋找API
API在此
這是使用post,會在下個章節說明
5.
自己尋找API
回傳的內容

此時就可以透過解析巢狀結構來獲取想要的資料
練習題:
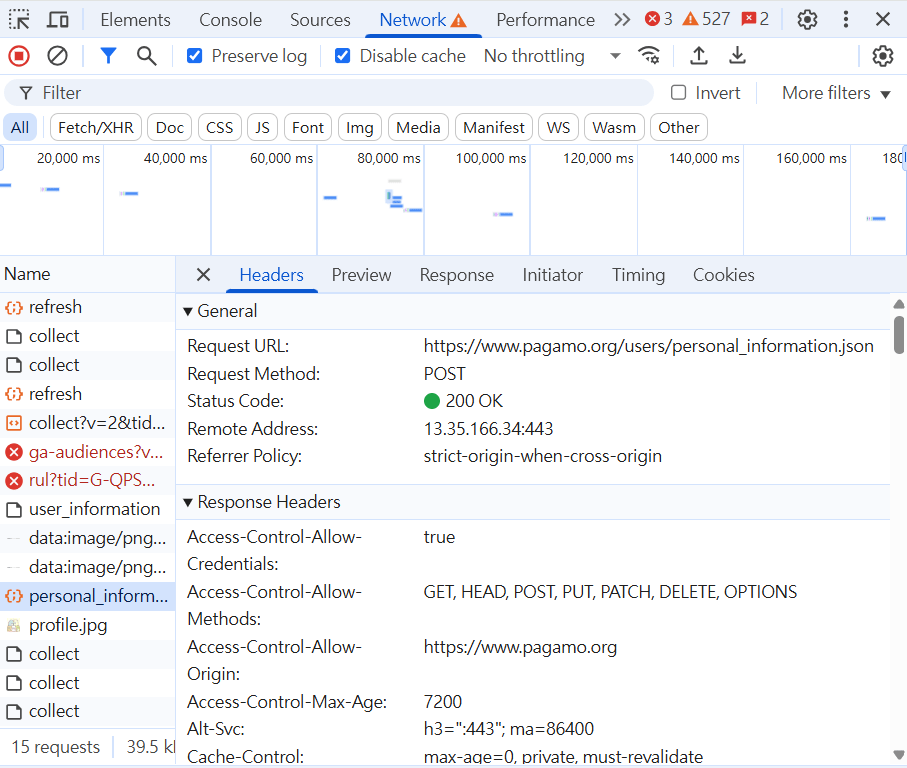
去教育部抓取編號為353302的學校名稱
# PRESENTING CODE
答案:
import requests
a = requests.get("https://stats.moe.gov.tw/files/school/114/high.json").json()
for i in a:
if i['代碼'] == "353302":
print(i['學校名稱'])用for迴圈遍歷,如果代碼為353302
就印出"學校名稱"
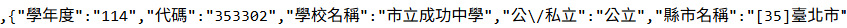
市立成功中學- 透過各個地方的API,能方便取得很多資料
- 原則上,會自己尋找API之後,能抓取更多資料
- ex.動態(後來載入的)資料
結語
requests.POST
複習一下
| 屬性 | 用途 | 範例 |
|---|---|---|
| requests.get | 向伺服器【請求】資料 | 瀏覽網頁 |
| request.post | 向伺服器【發送】資料 | 提交表單 |
剛剛get ➡️ 他提交給我們
現在post ➡️ 我提交給他們
透過瀏覽器互動
平時上網
資料傳送
回復結果
發送我們的資料
回復【我收到了】
網路爬蟲
通常用於:
- 提交表單(ex.登入、註冊、意見回饋)
- 上傳檔案
requests.POST
# PRESENTING CODE
url = "https://XXX.com/api/sign_in"
response = requests.post(url, data=data)基本語法
用POST
要發送的資料
要發送到哪個網址?哪個網址會接收帳密?
requests.POST
傳到首頁 Yahoo奇摩 ?
❌
- 首頁只負責給你網站資料
- 不負責接收帳密
- 帳密要接傳到後台
✔️傳到接收帳密的API
requests.POST
不同API處理不同收到的資料
你要先【找到發送到哪】
而每個位置有不同的網址
處理登入
處理攻擊
處理好友
requests.POST
ex.登入要發送到
https://www.XXXXX.com/api/sign_in
修改個資要發送到
https://www.XXXXX.com/api/user_settings
找到要發送的API位置

前面講過,使相同方式尋找API 並 post出去
自己尋找API 範例2
1.點擊會發送資料的物件
ex.按下登入會送出密碼
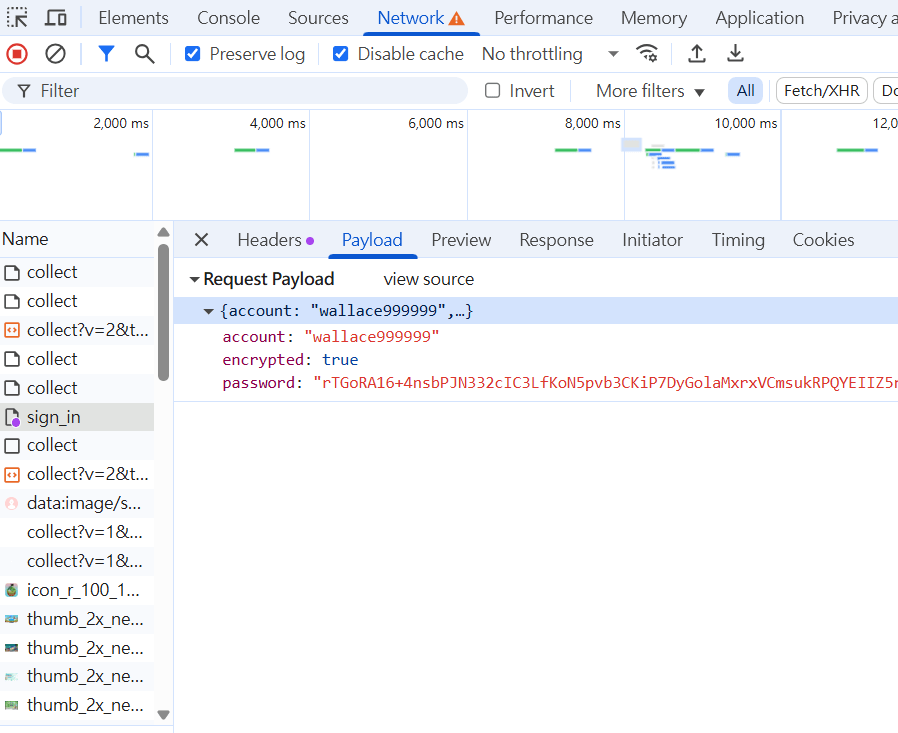
POST帳密出去
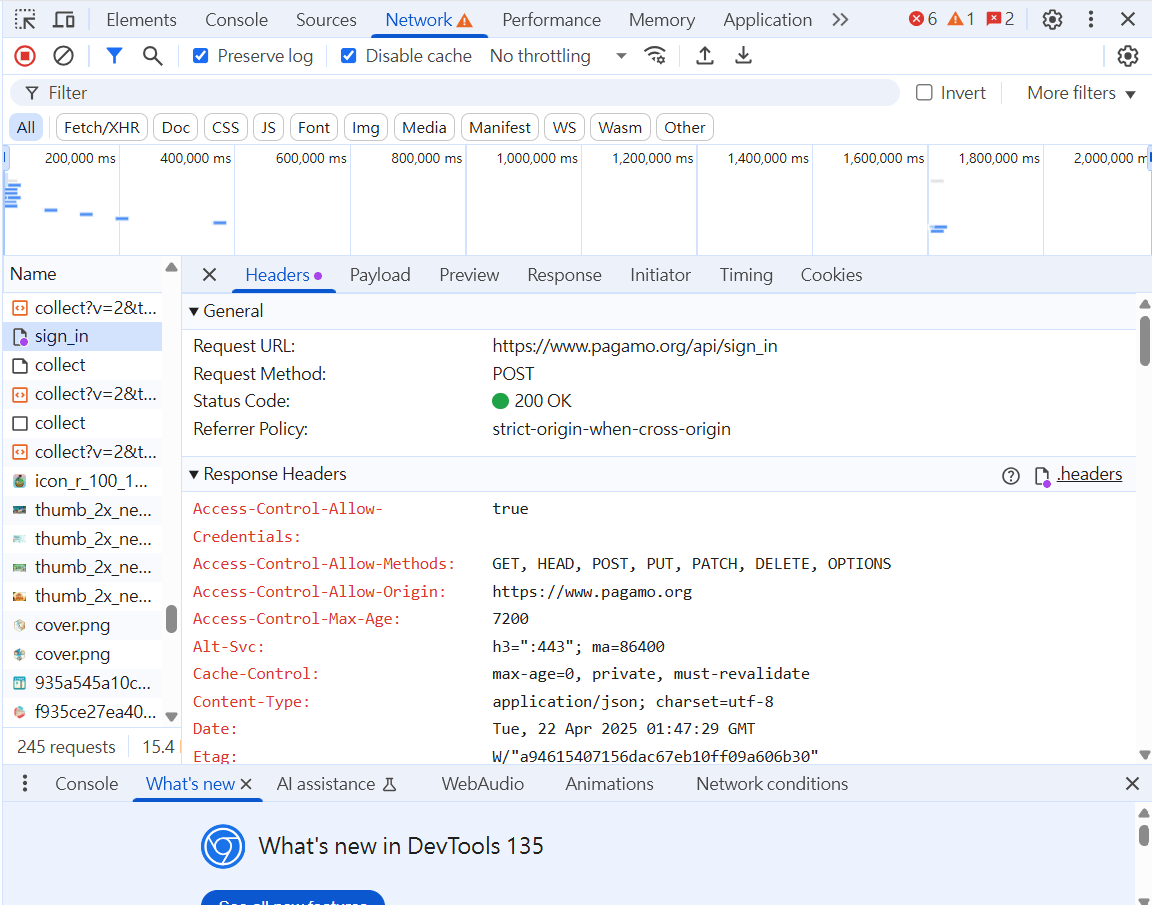
自己尋找API 範例2
API在此
payload 發送出去的資料(帳密)
2.查看帳密發送到哪了
response 伺服器回復(是否登入成功)
自己尋找API 範例2
payload ➡️ 發送出去的資料
3.查看發送了甚麼
response 伺服器回復(是否登入成功)
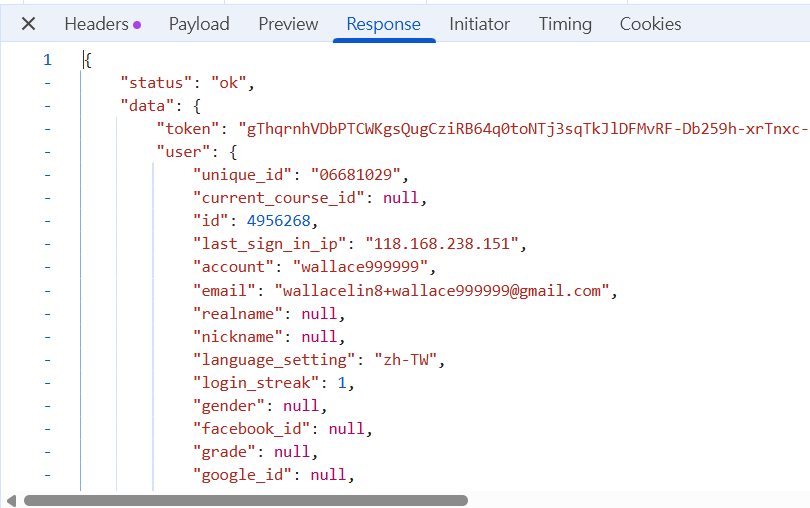
ok表示成功
可知發送出去的是一個json格式
requests.POST
# PRESENTING CODE
import requests
url = "https://www.pagamo.org/api/sign_in"
data = {
'account': 'wallace999999',
'encrypted': True,
'password': 'SQ3GcclkDIlmMulkfdpnUxSO1FssO0RBLPfrmFT5x2DuteYMSRr2luPaYJywYXRpLclcOckosmHWURjTYdIHMYFPTtZ3VT6WHNz+9p4hpf94NAAtKIic6tQn0uuI2B2PBGCMg88ZJ77CB8yqGumt/T5+ZbaueHHn42OWzCE1h6Xo8fSsRZnrQMXRkUwLbRojZ6FTa2yTcGMwblOia7ohULM/sDvOYXTXX8oMCSChvbUcXcpszmgegdnKj7KRmkOLuEYX3LcZjY1c34B70R8HYhBsWZnLjdxHC7f70OfcKplnWOPHpOPIy8+SMATJoBF4Eq1/jvPduaf8W4PfucXKzA=='
}
Useragent = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.post(url, data=data, headers=Useragent)
print(response.text)要發送的網址
發送的資料
發送到【接收帳密的端口】
- POST是發送資料
- 把要發送的資料放在data這個值
- 使用json格式
語法範例 : 登入
反反爬蟲
requests.POST
# PRESENTING CODE
系統回復: 會自轉化成Python字典

剛剛的網頁回復:
✔️資料相同
requests.POST應用
範例:遊戲外掛
自動開PaGamO的【假期模式】


requests.POST應用
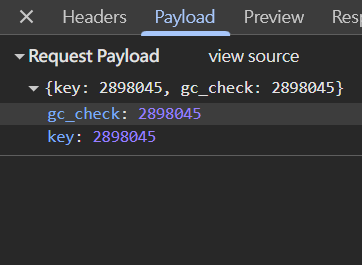
事實上,只是POST到API兩個小數字而已
requests.POST應用
事實上,只是POST到API兩個小數字而已

✔️相同效果
# PRESENTING CODE
import requests
info_url = 'https://www.pagamo.org/users/personal_information.json'
s = requests.Session()
def open_hoilday():
#登入
login_url = 'https://www.pagamo.org/api/sign_in'
login_data = {'account': "wallace999999", 'encrypted': True, 'password': "SQ3GcclkDIlmMulkfdpnUxSO1FssO0RBLPfrmFT5x2DuteYMSRr2luPaYJywYXRpLclcOckosmHWURjTYdIHMYFPTtZ3VT6WHNz+9p4hpf94NAAtKIic6tQn0uuI2B2PBGCMg88ZJ77CB8yqGumt/T5+ZbaueHHn42OWzCE1h6Xo8fSsRZnrQMXRkUwLbRojZ6FTa2yTcGMwblOia7ohULM/sDvOYXTXX8oMCSChvbUcXcpszmgegdnKj7KRmkOLuEYX3LcZjY1c34B70R8HYhBsWZnLjdxHC7f70OfcKplnWOPHpOPIy8+SMATJoBF4Eq1/jvPduaf8W4PfucXKzA=="}
Useragent = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
print('正在登入...')
login_resp = s.post(login_url, data=login_data, headers=Useragent).json()
gc_id = login_resp['data']['gtm_info']['gc_id']
print(gc_id)
headers = { "Origin": "https://www.pagamo.org", "Referer": f"https://www.pagamo.org/map?course_code=TMGQOQS7" ,"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"} # 將數據以JSON格式傳遞
# 發送POST請求
response = s.post("https://www.pagamo.org/gamecharacters/holiday_mode", json={'gc_check': gc_id, 'key': gc_id}, headers=headers)
print(response.text)
open_hoilday()requests.POST應用
範例程式碼:
登入
POST到holiday(假期模式)
練習題:
對https://httpbin.org/post發送一組帳號密碼,觀察他的回應
提示: 可以透過前面簡報範例進行修改
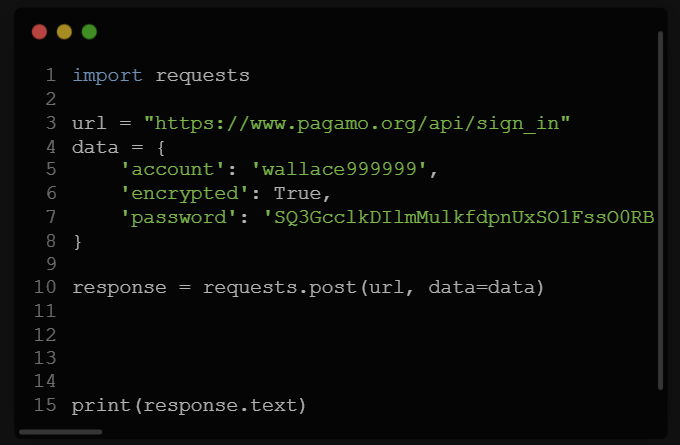
# PRESENTING CODE
答案:
import requests
data = {'username': 'wallace999999', 'password': '12345678'}
response = requests.post('https://httpbin.org/post', data=data)
print(response.text){
"args": {},
"data": "",
"files": {},
"form": {
"password": "12345678",
"username": "wallace999999"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Content-Length": "40",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.32.3",
"X-Amzn-Trace-Id": "Root=1-6807af2e-736618625aab73be70d21e72"
},
"json": null,
"origin": "111.249.209.22",
"url": "https://httpbin.org/post"
}會把你發送的東西傳回來,代表他有收到
{
"args": {},
"data": "",
"files": {},
"form": {
"password": "12345678",
"username": "wallace999999"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Content-Length": "40",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.32.3",
"X-Amzn-Trace-Id": "Root=1-6807af2e-736618625aab73be70d21e72"
},
"json": null,
"origin": "111.249.209.22",
"url": "https://httpbin.org/post"
}會把你發送的東西傳回來,代表他有收到
蝦?什麼網站會做這種蠢事情?把你傳回來?
https://httpbin.org
但至少你現在學會POST了
# PRESENTING CODE
httpbin.org
httpbin.org
- 學完了基本的GET和POST
- 除了一直尋找網站來抓
- 還有甚麼可以練習的地方嗎?
✔️有
❗httpbin.org
httpbin.org介紹
- 開源的 HTTP 測試網站
- 讓開發者測試、偵錯和學習 HTTP 協議
-
由 Python 的 Flask 框架建構
主要用途:讓開發者測試 HTTP 請求與回應
httpbin.org功能
-
測試不同 HTTP 請求:
-
GET, POST, PUT, DELETE, PATCH, OPTIONS
-
-
檢視回傳的資料格式 / headers
-
模擬伺服器回應,例如:
-
模擬延遲 (/delay)
-
模擬錯誤 (/status/404)
-
回傳指定的 JSON (/json)
-
⬅️剛剛出現的
⬅️測試是否會崩潰
⬅️前面出現的 抓取個資
httpbin.org


模擬各種端口
各種類型爬蟲都可以試
開源 ?
放在公開的網路平台上,讓你自己也可以使用
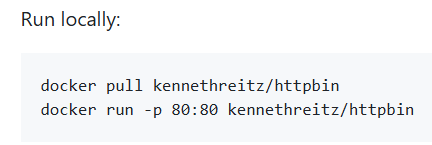
提供啟動方法:
robots.txt協議
robots.txt
路上有交通規則

爬蟲也有行為規範

robots.txt
- 告訴爬蟲本網站允許存取的範圍
- 阻止爬蟲存取特定頁面或目錄
- 避免爬蟲過度請求
存放於網站的根目錄下
ex.
https://www.xxxxx.com/robots.txtrobots.txt
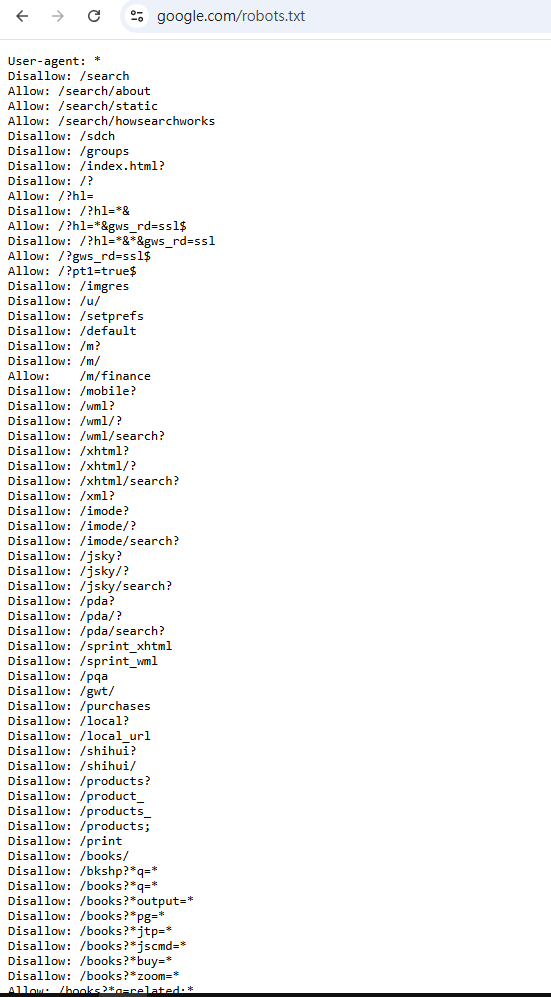
因為他只是一份文件,不具強制力,惡意爬蟲可能會無視
robots.txt
語法簡介
- 每條規則佔一行
- 大小寫無規定,但建議統一使用小寫
- 註解使用
#符號 - 路徑以
/開頭 - 萬用字元
*
robots.txt
語法簡介
禁止所有爬蟲存取整個網站:
禁止特定爬蟲存取特定目錄:
允許特定爬蟲存取特定目錄:
User-agent: *
Disallow: /User-agent: BadBot
Disallow: /secret/User-agent: GoodBot
Allow: /public/
Disallow: /# PRESENTING CODE
robots.txt
語法簡介
-
User-agent:指定適用於哪些爬蟲 -
Disallow:禁止爬蟲存取的路徑或目錄 -
Allow:允許爬蟲存取的路徑或目錄
User-agent: GoodBot
Allow: /public/
Disallow: /ex.
特別允許某一個
練習題:
抓取Yahoo網站的robots.txt,分析那些不被允許抓取
# PRESENTING CODE
答案:
不被允許:
Disallow: /p/
Disallow: /r/
Disallow: /bin/
Disallow: /includes/
Disallow: /blank.html
Disallow: /_td_api
Disallow: /_td-hl
Disallow: /_tdpp_api
Disallow: /_remote
Disallow: /_multiremote
Disallow: /_tdhl_api
Disallow: /_td_remote
Disallow: /_tdpp_remote
Disallow: /sdarla
Disallow: /digest
Disallow: /tdv2_fp
Disallow: /tdv2_mtls_fp
Disallow: /*?bcmt=*
Disallow: /tw_ms
Disallow: /nel_ms/可見他不允許我們抓取許多頁面
所以我們在沒有「偽裝」的時候進不去
selenium
接下來會換一個全新的東西
如果剛剛聽不懂的,現在可以重新認真聽了
⚡⚡⚡
selenium是甚麼

設定一個位置,自動幫你點擊
點擊精靈
Selenium簡介
Selenium簡介
1 2 3

4 5
點擊1號按鈕
Selenium簡介
一種網頁自動化瀏覽工具
它會自動開啟瀏覽器
模擬使用者操作:點擊、輸入、滾動等
缺點: 限用於網頁、瀏覽器
Selenium簡介

你可以把它想像成網軍 或像這樣
Selenium比較
跟剛剛學的request有何差別?
| requests | selenium | |
|---|---|---|
| 角色 | 快遞員 | 機器人 |
| 運作方式 | 直接到伺服器門口,拿到包裹(資料或網頁)就走,整個傳給你 | 坐在電腦前,打開瀏覽器,模仿人類的點擊、輸入等所有操作 |
| 速度 | 快 (只需處理資料) | 慢 (要開啟瀏覽器) |
| 主要用途 | 獲取數據:呼叫 API、抓取靜態網頁內容 | 自動化操作:自動登入、填表單、玩遊戲 |
| 反爬蟲 | 低 (用User-Agent) | 高 (本來就像真人) |
Selenium實際應用
自動登入網站、填寫表單、搶票
無法用 API 抓取數據的地方(ex.社交媒體水軍自動操作)
實際範例: 網路上的搶票系統
Selenium實際應用-搶票程式
Selenium實際應用-搶票程式
裡面的程式碼?
就是用Selenium
Selenium實際應用-自動登入
再來一個範例
是用Selenium
Selenium
準備好來學這個酷東西了嗎 ?
selenium初探
pip install selenium# PRESENTING CODE
selenium安裝
- Python外部函式庫
在終端機輸入 :
# PRESENTING CODE
selenium第一步
引入函式庫:
import seleniumselenium瀏覽器安裝
使用selenium需要使用專用的瀏覽器 chrome driver
步驟1: 前往「設定→關於chrome」記下自己的chrome版本型號
(在第一行)
步驟2: 前往 https://googlechromelabs.github.io/chrome-for-testing/
下載與自己相同版本的chrome driver型號
selenium瀏覽器安裝
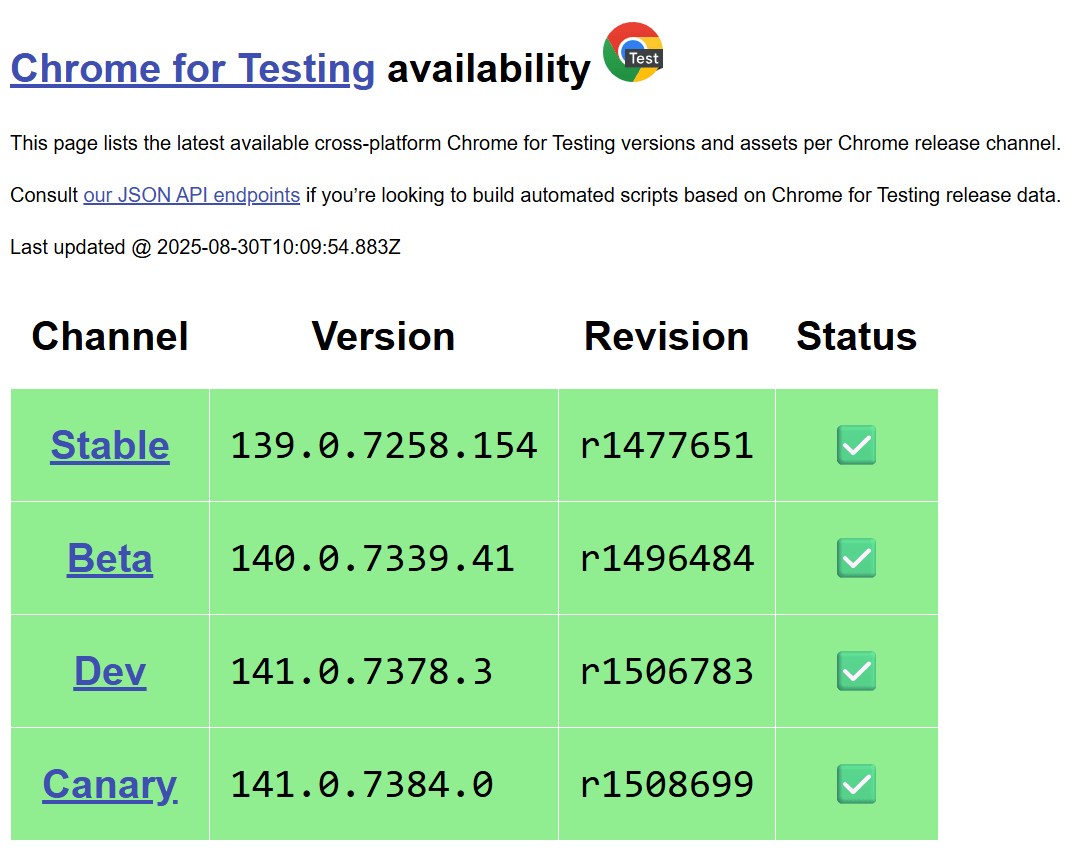
範例: 假設我的型號是139.0.7258.155
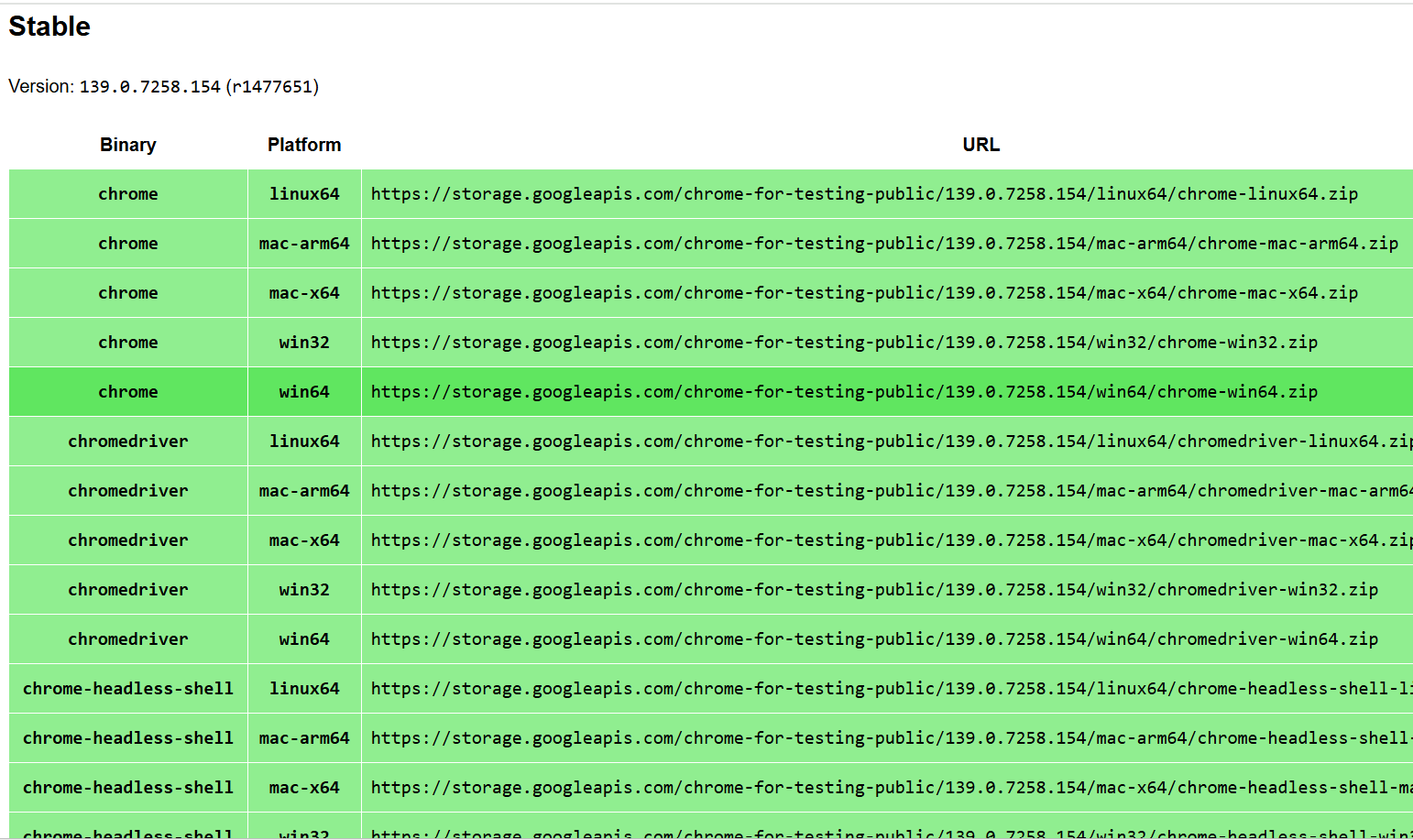
將win64版的連結複製貼上到瀏覽器
End.
網路爬蟲
By wallace Lin

